Pressecommuniqué

De Portal eluxemburgensia.lu dréit all déi vun der Nationalbibliothéik digitaliséierte Ressourcen zesummen a krut elo eng nei Recherchefunktioun. Vun elo un kënnen d’Benotzer hir Recherche der Sprooch no filteren, wéi zum Beispill no Däitsch, Franséisch oder Lëtzebuergesch.
D’Zeitungen, Bicher an historesch Zäitschrëften, déi vun der BnL digitaliséiert ginn, zeie vun der méisproocheger Kultur zu Lëtzebuerg a rassembléieren oft verschidde Sproochen op eng nämmlecht Säit. Déi nei Filteroptioun erlaabt et engem Benotzer, dee léiwer just Artikelen an enger bestëmmter Sprooch liese wëll, all Inhalter op eluxemburgensia ze filteren an seng Recherche nach méi ze cibléieren.
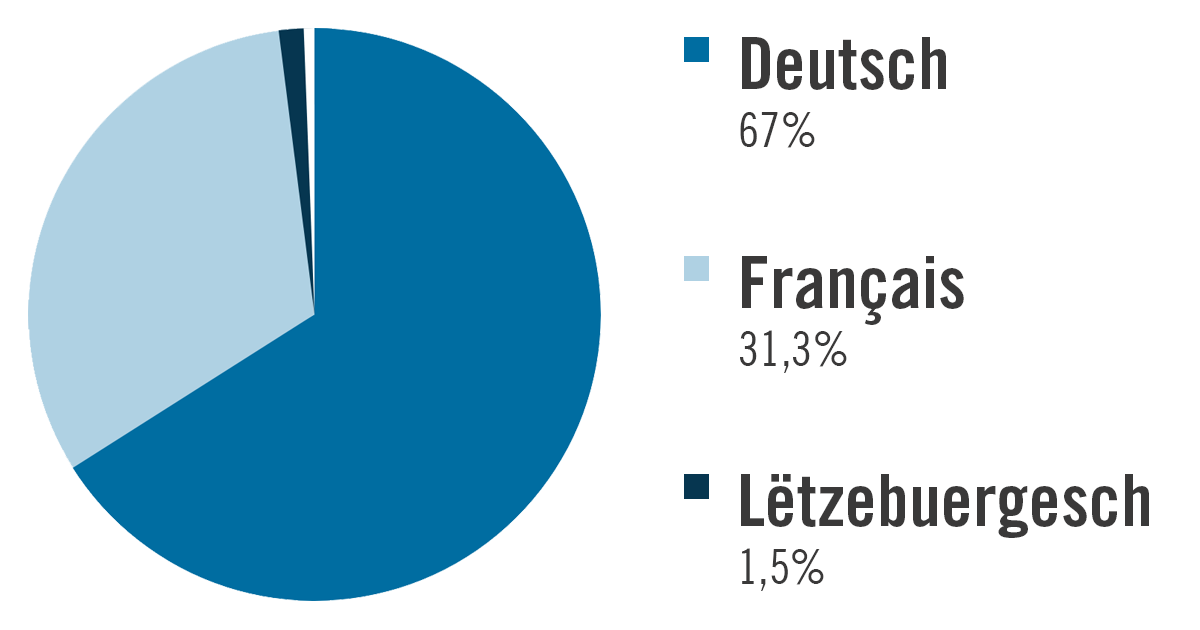
D’Haaptsproochen um Portal sinn Däitsch, mat 67% vum Total, suivéiert vu Franséisch, mat 31.3%. Lëtzebuergesch ass an enger vill méi klenger Proportioun representéiert, mat knapps iwwer 118.123 Artikelen (entsprécht 1,5%), wärend Englesch, mat 10.149 Artikelen (entsprécht 0,1%) als minoritär ugesi ka ginn. 14 weider manner present Sprooche goufen detektéiert, esou wéi Laténgesch, Italieenesch, Portugisesch an Polnesch.
Wärend sech d’Determinéiere vun der Sprooch fir Monographien op bibliographesch Notizze berufft, esou ass dësen Exercice méi schwéier fir Zeitungsartikelen, fir déi et esou Donnéeën net ginn. Wëll d’optesch Zeechenerkennung (OCR) nach net perfekt ass a wëll verschidden Zorte vun Texter, wéi zum Beispill Lëschte vun Nimm, keng identifizéierbar Sprooch hunn, notzt dee vun der BnL entwéckelten Algorithmus zousätzlech Heuristiken:
Fir Sprooche mat manner wéi 1.000 Artikele ginn d’Texter per Hand kontrolléiert fir ze kucken op den Algorithmus déi korrekt Sprooch determinéiert huet. Dëst erlaabt et eng gewësse Prezisioun fir manner genotzte Sproochen ze erhalen. Déi aner Artikele ginn net manuell iwwerpréift an et bleiwen Imperfektiounen. Weider ginn et och méisproocheg Artikelen (z. B. Mat engem Deel op Franséisch an engem Deel op Däitsch) fir déi eng dominant Sprooch gewielt gëtt. Schlussendlech ginn et och verschiddenen Inhalter, wéi zum Beispill Lëschte mat Sportresultater, déi sech net fir eng Sproochenbestëmmung ubidden.
IKT-Fachleit an Entwéckler wäerten et ze schätze wëssen, datt d’Sproocheninformatiounen an d’Metadaten vun den digitaliséierten Dokumenter opgeholl goufen a fir analytesch Zwecker benotzt kënne ginn. Tatsächlech leeën d’Algorithme vun der maschineller Sproocheveraarbechtung eng gutt Grondlag fir d’Entwécklung vun neien Outile fir d’Analyséiere vun historeschen Texter.
Aktualiséiert den