Communiqué de presse

Le portail eluxemburgensia.lu rassemble toutes les ressources numérisées par la Bibliothèque nationale et a été doté d’une nouvelle facette de recherche. Désormais, les utilisateurs peuvent filtrer leur recherche par langue, par exemple, l’allemand, le français ou le luxembourgeois.
Les journaux, livres et revues historiques numérisées par la BnL témoignent de la culture de multilinguisme présente au Luxembourg et rassemblent souvent différentes langues sur une même page. La nouvelle option de filtrage permet à un utilisateur, qui préfère lire des articles dans une langue spécifique, de filtrer l’ensemble des contenus sur eluxemburgensia.lu et de cibler d’avantage sa recherche.
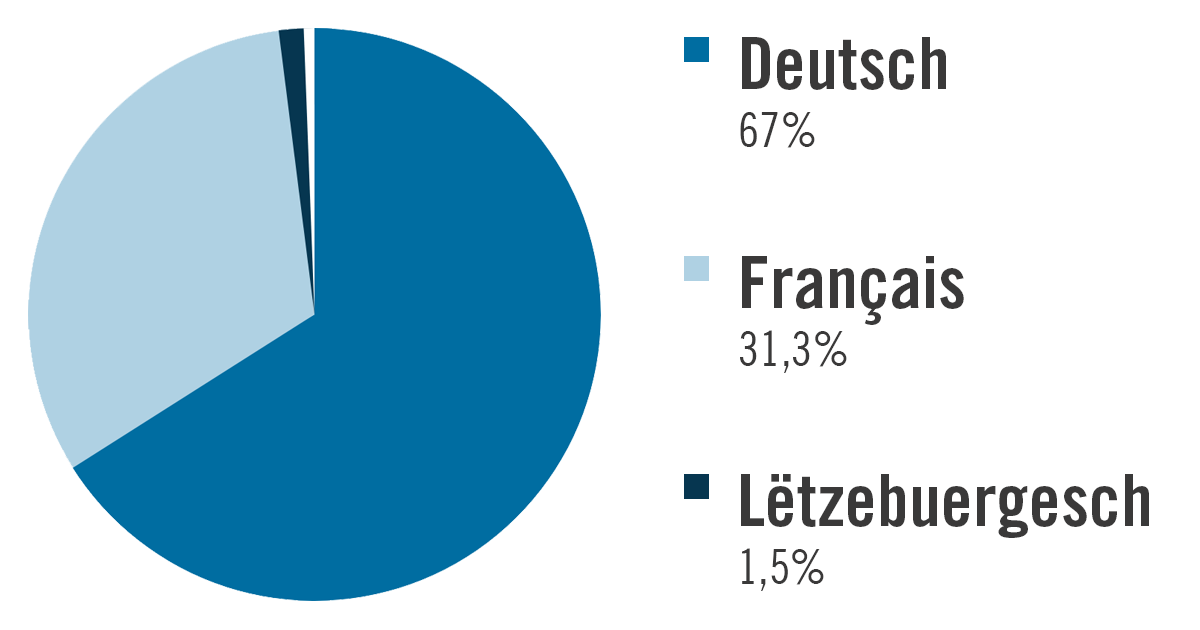
Les langues principales sur le portail sont l’allemand, qui compte pour 67% du total, suivi du français à hauteur de 31,3%. Le luxembourgeois est représenté dans une proportion nettement inférieure, avec un peu plus de 118.123 articles (soit 1,5%), tandis que l'anglais, avec 10.149 articles (soit 0,1%), est considéré comme minoritaire. 14 autres langues ont été détectées dont le latin, l’italien, le portugais et le polonais.
Tandis que la détermination de la langue pour les monographies est faite à base des notices bibliographiques, l’exercice s’avère plus compliqué pour les articles des périodiques pour lesquels de telles données n’existent pas. Comme la reconnaissance optique de caractères (OCR) n’est pas encore parfaite et que certains types de textes, tels que des listes de noms, n’ont pas de langue indentifiable, l’algorithme développé par la BnL utilise plusieurs heuristiques complémentaires :
Pour les langues avec moins de 1.000 articles, les textes sont revus à la main pour vérifier si l’algorithme a en effet déterminé la bonne langue. Ceci permet de garder une certaine précision pour les langues marginales. Pour les autres articles, la langue n’est pas revue manuellement et il reste des imprécisions. En outre, il y a des articles multilingues (p.ex. une partie en français, une autre en allemand) pour lesquels la langue dominante est choisie. Finalement, certains contenus, tels que des listes de résultats sportifs, ne se prêtent pas à ce genre de processus de détermination de langue.
Les professionnels des NTIC et développeurs apprécieront que les informations de langue aient été intégrées dans les métadonnées des documents numérisés et qu’elles puissent être utilisées à des fins analytiques. En effet, les algorithmes du traitement automatique de langue posent de bonnes bases pour le développement de nouveaux outils d’analyse de textes historiques.
Dernière modification le