Pressemitteilung

Das Portal eluxemburgensia.lu vereint alle von der Nationalbibliothek digitalisierten Ressourcen und wurde mit einer neuen Suchfunktion ausgestattet. Von nun an können die Nutzer ihre Suche nach Sprachen filtern, zum Beispiel Deutsch, Französisch oder Luxemburgisch.
Die von der BnL digitalisierten historischen Zeitungen, Bücher und Zeitschriften zeugen von der in Luxemburg vorhandenen Kultur der Mehrsprachigkeit und vereinen oft verschiedene Sprachen auf einer Seite. Die neue Funktion ermöglicht es zum Beispiel einem Nutzer, der lieber nur eine der Sprachen lesen möchte, alle Inhalte auf eluxemburgensia.lu zu filtern und seine Suche noch gezielter zu gestalten.
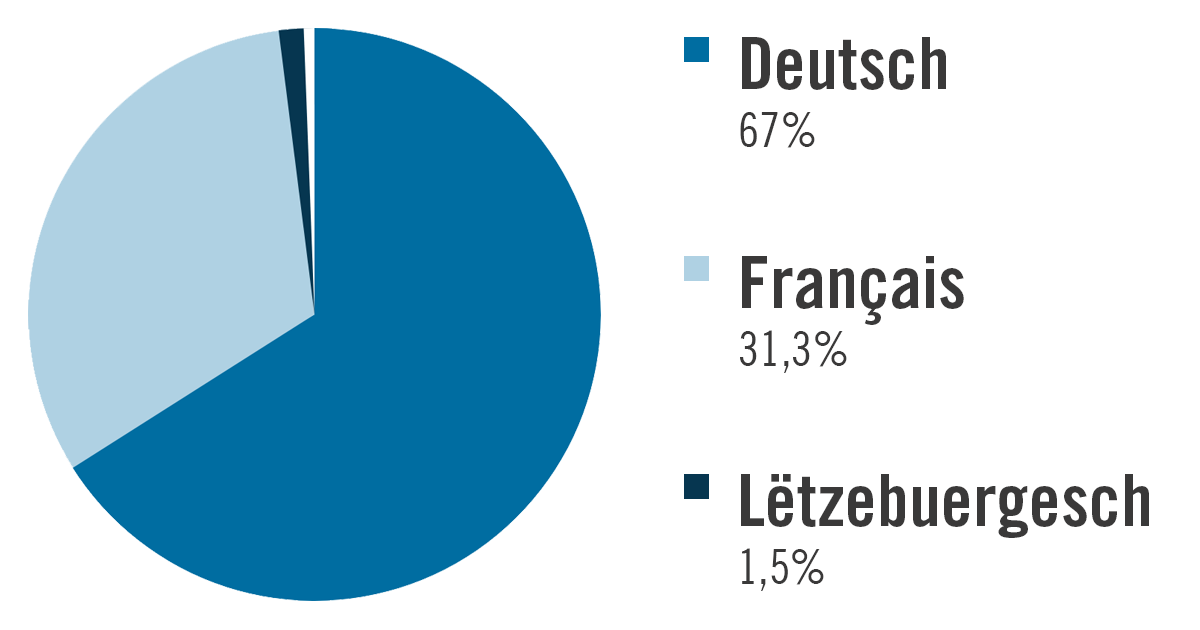
Die beiden Hauptsprachen auf dem Portal sind Deutsch, das 67% der Gesamtsumme ausmacht, gefolgt von Französisch mit 31,3%. Luxemburgisch ist mit etwas mehr als 118 123 Artikeln (oder 1,5 %) in einem deutlich geringeren Anteil vertreten, während Englisch mit 10 149 Artikeln (oder 0,1 %) als minoritär gilt.
Während die Sprachbestimmung bei Monografien anhand der bibliografischen Einträge erfolgt, ist die Vorgehensweise bei Zeitschriftenartikeln, für die es keine derartigen Daten gibt, komplizierter. Da die optische Zeichenerkennung (OCR) noch nicht perfekt ist und manche Texte, wie z. B. Namenslisten, keine identifizierbare Sprache haben, verwendet der von der BnL entwickelte Algorithmus mehrere sich ergänzende Heuristiken:
Bei Sprachen mit weniger als 1 000 Artikeln werden die Texte von Hand überarbeitet, um zu überprüfen, ob der Algorithmus tatsächlich die richtige Sprache ermittelt hat. Dadurch bleibt eine gewisse Genauigkeit für Randsprachen erhalten. Bei den anderen Artikeln wird die Sprache nicht manuell überprüft und es bleiben Ungenauigkeiten. Darüber hinaus gibt es mehrsprachige Artikel (z. B. ein Teil auf Französisch, ein anderer auf Deutsch), bei denen die überwiegende Sprache gewählt wird. Schließlich gibt es Inhalte, wie z. B. Listen mit Sportergebnissen, die sich nicht für diese Art von Sprachbestimmungsprozess eignen.
IKT-Fachleute und Entwickler werden zu schätzen wissen, dass die Sprachinformationen in die Metadaten der digitalisierten Dokumente integriert wurden und nun auch für analytische Zwecke verwendet werden können. Tatsächlich sind die Algorithmen der maschinellen Sprachverarbeitung oft sprachabhängig, und diese Arbeit legt eine gute Grundlage für die Entwicklung neuer Werkzeuge zur Analyse historischer Texte.
Zum letzten Mal aktualisiert am